流式计费实战:Stream 模式下如何不阻塞主链路计算 Token
Streaming Billing in Practice: Counting Tokens Without Blocking the Main Pipeline
面试官必问的一道题:"开启了 stream=True,你的网关怎么知道消耗了多少 Token?流断了怎么办?"
这个问题之所以高频,是因为它击中了网关开发的高阶难点:你在转发流式数据的同时,必须在后台完成计费——而且绝对不能阻塞用户的打字机体验。
一、流式计费为什么难
非流式(stream=False)计费很简单——大模型返回完整 JSON,里面直接带了 usage.total_tokens,你拿这个数字入库就行。
但流式(stream=True)完全是另一回事:
- 大模型是逐 chunk 返回数据的,每个 chunk 只有
delta.content - 最后一个 chunk 才带 usage 信息(finish_reason + token 统计)
- 中间的 chunk 只是文本片段,不包含任何 Token 计数
- 你不能等最后一个 chunk 到了再一次性处理——那会让计费逻辑卡住最后一段文本的传输
二、核心解法:AsyncGenerator 包装器
LiteLLM 的源码解法非常优雅。它不直接把厂商的 HTTP Chunk 流透传给客户端,而是用一个 Python 异步生成器(AsyncGenerator) 把整个流包起来:
async def chunk_processor(response_stream):
complete_text = "" # 在网关内存中拼接完整文本 / Concatenate full text in gateway memory
async for chunk in response_stream:
# 1. 解析厂商的 chunk,转换为 OpenAI 格式 / Parse vendor chunk, convert to OpenAI format
openai_chunk = format_to_openai(chunk)
# 2. 提取文本片段,拼接到完整文本 / Extract text fragment, append to full text
complete_text += extract_text(openai_chunk)
# 3. 立即 yield 给客户端(用户看到打字机效果) / Immediately yield to client (user sees typewriter effect)
yield openai_chunk
# 4. 流完全结束后,触发计费计算 / After stream ends, trigger cost calculation
# (这时 complete_text 已经是完整回复了) / (complete_text now holds the full response)
trigger_cost_calculation(complete_text)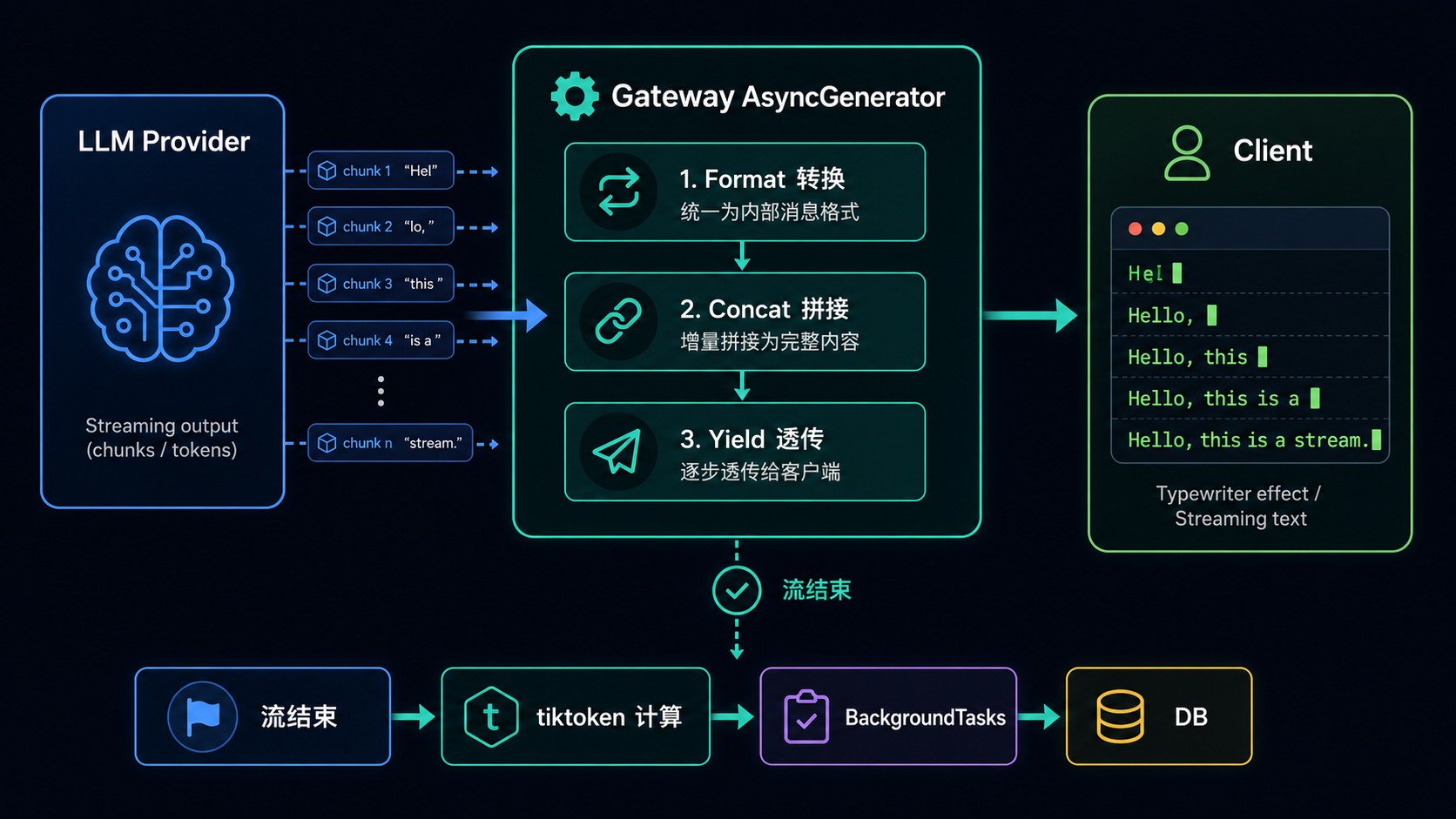
这个设计的关键在于:yield 不阻塞流水线。网关在每收到一个 chunk 时,做三件事——格式转换、文本拼接、yield 给客户端——全部是同步的、低延迟的。真正的计费计算被推迟到了流结束之后。
三、Token 计算:tiktoken 离线计算
流结束后,网关内存里已经有了完整的 complete_text 和原始 prompt。源码调用 litellm.token_counter(),底层使用 OpenAI 开源的 tiktoken 库:
# tiktoken 离线计算(未发生额外网络请求)
# tiktoken offline calculation (no additional network request)
import tiktoken
encoding = tiktoken.encoding_for_model("gpt-4o")
prompt_tokens = len(encoding.encode(prompt_text))
completion_tokens = len(encoding.encode(complete_text))
total_tokens = prompt_tokens + completion_tokens为什么用 tiktoken 离线计算而不是依赖 API 返回的 usage?两个原因:
- 不同厂商的 usage 格式不一致:OpenAI 返回
usage.total_tokens,但某些厂商的返回结构完全不同,甚至不返回 usage - Reasoning Tokens(推理 Token):DeepSeek-R1、o1 等模型有隐蔽的 reasoning_tokens,它们是收费的但不一定出现在 completion_tokens 里
四、异步落库:BackgroundTasks 不阻塞主链路
Token 算完了,但写数据库肯定是 I/O 操作。如果直接在请求线程里写 PostgreSQL,会增加用户的响应延迟。
LiteLLM 的做法:把数据库写入操作挂载到 FastAPI 的 BackgroundTasks 上。这是 FastAPI/Starlette 提供的一个机制——后台任务会在响应已返回给客户端之后才执行。
# 伪代码示意 / Pseudocode illustration
from fastapi import BackgroundTasks
async def completion_handler(request, background_tasks: BackgroundTasks):
# ... 处理请求,拿到 token_count ... / ... process request, get token_count ...
# 将计费写入挂载为后台任务——不阻塞响应
# Mount billing write as background task — does not block the response
background_tasks.add_task(
write_cost_to_db,
user_id=user_id,
model=model,
total_tokens=token_count,
)
return response # 客户端立即收到响应,后台任务稍后执行 / Client gets response immediately, background task runs later五、我实习中的实战:日报系统
在实习期间,我基于 LiteLLM Gateway 的日志数据,开发了一套自动化日报系统(daily_usage_report.py)。核心逻辑:
# 1. 从 Gateway 拉取原始日志 / Fetch raw logs from the Gateway
def fetch_spend_logs(start_date, end_date):
url = f"{BASE_URL}/spend/logs"
params = {"limit": 50000, "startTime": st, "endTime": et}
r = httpx.get(url, params=params, headers=headers)
return r.json()["logs"]
# 2. 从日志中提取 Token——兼容多种 usage 格式
# Extract tokens from logs — compatible with multiple usage formats
def _extract_tokens_from_log(log):
# 从顶层 total_tokens 取 / Try top-level total_tokens
# 从 usage.total_tokens 取 / Try usage.total_tokens
# 从 metadata.usage_object.total_tokens 取 / Try metadata.usage_object.total_tokens
# 加上 reasoning_tokens(DeepSeek R1 等) / Add reasoning_tokens (DeepSeek R1, etc.)
...
# 3. 按用户/团队/模型维度聚合,生成 Markdown 日报
# Aggregate by user/team/model dimensions, generate Markdown daily report
# 4. 通过飞书 Webhook 自动推送到团队群
# Auto-push to team chat via Feishu Webhook这套系统让我能精确回答"这个月每个团队花了多少钱""哪个模型用量最大"等问题。实习结束时,网关累计处理了 1 亿+ Token。
六、流断开的处理
面试官可能会追问:"如果流输出到一半,客户端断开连接了怎么办?"
这时网关内存中已经拼接了部分文本。源码中会通过 try/except 捕获连接断开异常,仍然触发计费计算——基于已拼接的部分文本计算 Token,保证即使异常断开也能记录部分消耗。
总结
流式计费的三个关键点:
- AsyncGenerator 包装:在 yield 的同时内存拼接,不阻塞数据流
- tiktoken 离线计算:不依赖厂商的 usage 格式,保证跨模型一致性
- BackgroundTasks 异步落库:计费写入不增加用户延迟
这三板斧下来,你就拥有了一个既快又准的流式计费系统。